Technology
Smart Tech News, Gadgets, AI Updates & Digital World Insights

Geoffrey Hinton Military AI Reversal 2026
The Geoffrey Hinton military AI reversal 2026 marks a stunning shift as the Nobel Prize-winning "Godfather of AI" now endorses military AI applications, reversing his life-long skepticism amid escalat...
 Sk Jabedul Haque
Sk Jabedul Haque

Small Reasoning Models vs Giant LLMs: Why Domain-Specific AI Is Outperforming in 2026
For three years, the AI narrative was simple: bigger models win. More parameters, more GPUs, more data, more capital. But in 2026, that paradigm is shattering. Small reasoning models — compact, domain...
Sk Jabedul Haque

TurboQuant vs GPTQ vs AWQ: Why Google's Method Needs No Retraining
TurboQuant is the only LLM quantization method that needs no calibration data, no retraining, and no dataset-specific tuning. GPTQ and AWQ both require a calibration dataset to find optimal quantizati...
Sk Jabedul Haque
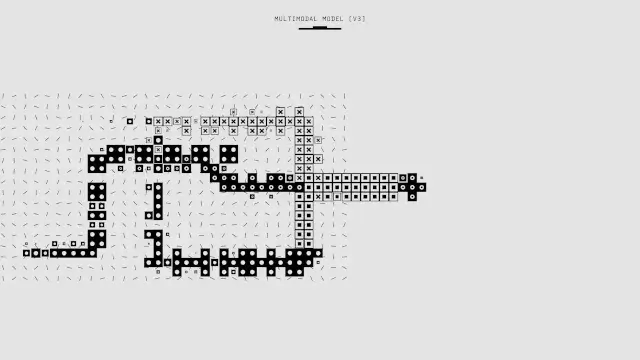
PolarQuant + QJL: The Two-Stage Secret Behind TurboQuant's Zero Loss
TurboQuant achieves zero accuracy loss through two complementary algorithms: PolarQuant (random rotation + polar transform) and QJL (1-bit residual correction). Together, they compress KV cache 6x wit...
Sk Jabedul Haque

TurboQuant 3-Bit Quantization: Zero Accuracy Loss Explained
Google Research's TurboQuant compresses LLM KV cache to 3 bits with zero accuracy loss — achieving 6x memory reduction and 8x faster attention computation without any model retraining. How do you run ...
Sk Jabedul Haque
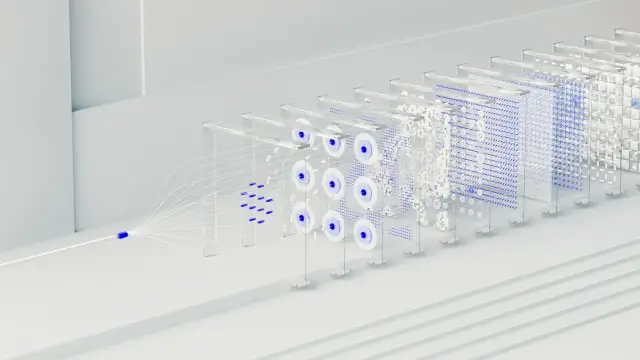
TurboQuant Explained: How Google Cut LLM Memory by 6x Without Losing Accuracy
TurboQuant is Google Research's quantization algorithm that cuts LLM memory usage by 6x without accuracy loss. By combining PolarQuant (weight quantization) and QJL Transform (KV cache compression), i...
Sk Jabedul Haque
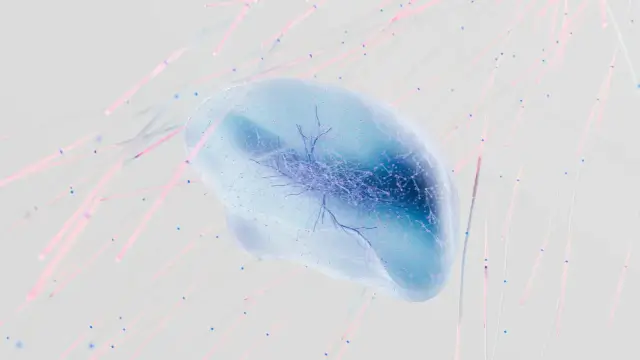
TurboQuant Explained 2026: Run 3x Larger AI Models on Cheap Hardware
Yes, TurboQuant lets you run 3x larger AI models on your existing hardware without buying expensive GPUs. Using FP4 (MXFP4) quantization and KV cache compression, DeepSeek V4 runs 1.6 trillion paramet...
Sk Jabedul Haque