
What You'll Learn
- Attractor-Based Reasoning: Why stable fixed points in latent space are the key to solving extreme symbolic logic tasks.
- Test-Time Scaling Axes: How EqR uses depth (iterations) and breadth (stochastic trajectories) to bypass the limitations of feedforward models.
- Benchmark Breakthroughs: Analyzing the 99.8% accuracy on Sudoku-Extreme and the 93% success rate on Maze-Unique.
- Elastic Budget Inference: Implementation details of the "halting policy" that optimizes compute allocation based on task difficulty.
The pursuit of generalizable AI reasoning has historically been limited by the "static" nature of neural network inference. Standard models, even advanced ones like GPT-4 or Claude, typically process input in a fixed number of layers, regardless of the problem's difficulty. This often results in memorization-based failures when faced with "out-of-distribution" logical puzzles. As we explore the next generation of high-performance systems like Agent JIT Compilation, the focus has shifted toward test-time scaling—allowing the model to "think longer" to solve harder problems.
Published on May 20, 2026, and accepted at ICML 2026, the paper "Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning" (arXiv:2605.21488) introduces a formal framework for this concept. Equilibrium Reasoners (EqR) move away from the traditional feedforward paradigm toward iterative latent dynamical systems. By shaping a landscape where valid solutions act as "attractors" (stable fixed points), EqR enables a level of scalable reasoning that was previously impossible, achieving near-perfect scores on the most grueling symbolic benchmarks.
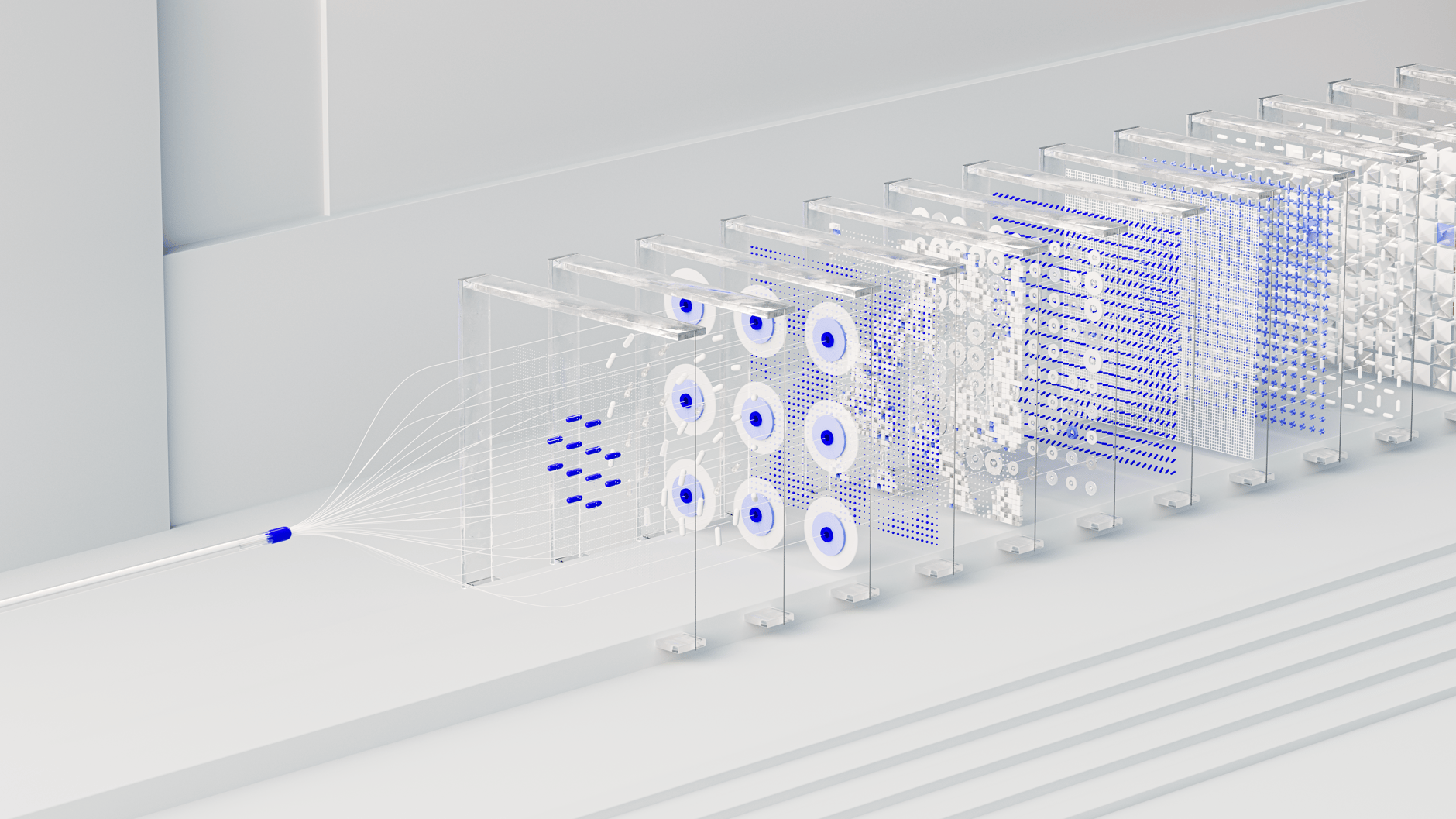
What are Equilibrium Reasoners (EqR)? The Attractor Perspective
At its core, EqR redefines reasoning as a dynamic search for stability. In a standard network, data flows linearly. In an Equilibrium Reasoner, the internal state (latent representation) is updated iteratively based on task-conditioned rules. The goal is to reach an "equilibrium" where further updates no longer change the state significantly. In this framework, a stable fixed point isn't just a mathematical convenience—it is the valid solution to the problem.
| Benchmark Task | Feedforward Models (Baseline) | Equilibrium Reasoners (EqR) |
|---|---|---|
| Sudoku-Extreme Accuracy | 2.6% | 99.8% |
| Maze-Unique Accuracy | 8.0% | 93.0% |
| Effective Compute Layers | Fixed (e.g., 64) | Up to 300,000 Layers |
| Reasoning Mechanism | Pattern Matching | Attractor Convergence |
The beauty of the attractor perspective is its mechanistic simplicity. By training the network to "admit" correct solutions as stable attractors and making their "basins of attraction" large and easy to reach, researchers have created a system that naturally generalizes. This approach avoids the common pitfalls of Vibe Coding security risks where models "hallucinate" valid-looking but logically incorrect answers based on statistical patterns.
Solving the "Stop-and-Think" Problem: How EqR Scales Compute
In current LLM frameworks, "thinking longer" usually means Chain of Thought (CoT) prompting or search-based agents. These methods are expensive and slow because they require multiple autoregressive generation steps. EqR solves this by scaling internal dynamics instead of external text generation. This is much faster and more memory-efficient because it reuses the same parameters across iterations—a technique known as weight-tied iterative modeling.
As noted in the 2026 Cisco State of AI report, only 29% of organizations are prepared for the security implications of such high-compute agentic deployments. Systems like EqR provide a safer alternative by keeping the reasoning "latent," which is less susceptible to the unauthenticated MCP server RCE vulnerabilities found in prompt-heavy architectures.
The Two Axes of Scaling: Depth vs. Breadth
The EqR framework scales test-time compute along two distinct axes, allowing it to adapt to varying task complexities:
- Axis 1: Depth (Iteration Depth): For harder tasks, the model simply runs more solver steps. Simple tasks converge in 1-5 steps, while extreme puzzles can scale up to the equivalent of 40,000 unrolled layers.
- Axis 2: Breadth (Stochastic Trajectories): If a model gets "stuck" in a local minimum, EqR can aggregate results from multiple random initializations. By injecting noise and leveraging stochasticity during training, the system learns to navigate diverse paths toward the same global attractor.
By unrolling up to an effective depth of 300,000 layers, EqR demonstrates that massive test-time scaling can overcome the "reasoning ceiling" of traditional models. This architectural choice aligns with the broader goal of building enterprise-grade AI security governance, where predictable and verifiable reasoning paths are required.
Elastic Budget Inference: Optimizing Compute for Every Task
A major efficiency innovation in EqR is Elastic Budget Inference. Universal, static compute budgets are wasteful; you don't need 40,000 layers to solve "2+2." EqR uses a "learned halting head" to monitor the latent dynamics. When the state converges to an attractor (indicating a stable solution), the model terminates computation early.
This "halting policy" ensures that extra compute is only allocated to instances that remain unresolved. This optimizes the compute-accuracy Pareto frontier, allowing EqR to maintain high speeds for simple queries while reserving its massive scaling power for the symbolic "Extreme" tasks where it truly shines.
Conclusion
Equilibrium Reasoners (EqR) represent a fundamental shift in how we build "intelligent" machines. By moving from pattern-matching feedforward networks to goal-oriented dynamical systems, researchers have unlocked a way to scale reasoning without external overhead. The jump from 2.6% to 99.8% accuracy on Sudoku-Extreme isn't just an incremental improvement—it is a proof of concept for scalable symbolic AI. As these models move into production, the ability to adaptively allocate compute while ensuring convergence to valid solutions will be the cornerstone of truly autonomous agents. For more on how to manage these powerful systems, see our guide to Multi-Agent Protocols.
Last Updated: May 28, 2026 | Source: ICML 2026 (Official Research Paper)